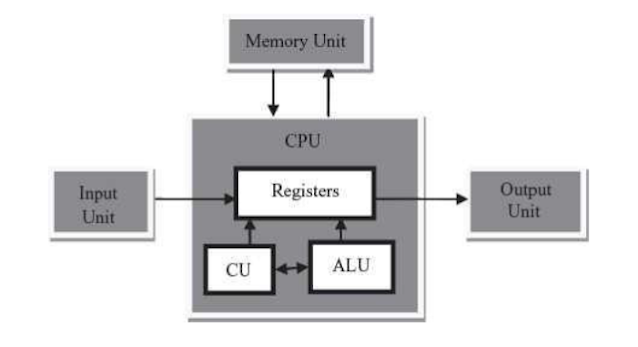
Alpha Numeric Character Data - ASCII, EBCDIC, UNICODE
The data entered as characters, number digits, and punctuation are known as alphanumeric data.It is tempting to think of numeric characters as somehow different from other characters, since numbers are often processed differently from text. Also, a number may consist of more than a single digit, and you know from your programming courses that you can store and process a number in numerical form within the computer. There is no processing capability in the keyboard itself, however. Therefore, numbers must be entered into the computer just like other characters, one digit at a time. At the time of entry, the number 1234.5 consists of the alphanumeric characters ‘‘1’’, ‘‘2’’, ‘‘3’’, ‘‘4’’, ‘‘.’’, and ‘‘5’’.
Any conversion to numeric form will take place within the computer itself, using software written for this purpose. For display, the number will be converted back to character form.The conversion between character and number is also not ‘‘automatic’’ within the computer. There are times when we would prefer to keep the data in character form, for example, when the numbers represent a phone number or an address to be stored and processed according to text criteria. Since this choice is dependent on usage within a program, the decision is made by the programmer using rules specified within the program language being used or by a database designer specifying the data type of a particular entity.
Since alphanumeric data must be stored and processed within the computer in binary form, each character must be translated to a corresponding binary code representation as it enters the computer. The choice of code used is arbitrary. Since the computer does not ‘‘recognize’’ letters, but only binary numbers, it does not matter to the computer what code is selected.Three alphanumeric codes are in common use. The three codes are known as Unicode, ASCII (which stands for American Standard Code for Information Interchange, pronounced ‘‘as-key’’ with a soft ‘‘s’’), and EBCDIC (Extended Binary Coded Decimal Interchange Code, pronounced ‘‘ebb-see-dick’’). EBCDIC was developed by IBM. Its use is restricted mostly to older IBM and IBM-compatible maniframe computers and terminals.The Web makes EBCDIC particularly unsuitable for current work. Nearly everyone today
uses Unicode or ASCII. Still, it will be many years before EBCDIC totally disappears from the landscape.
The ASCII code was originally developed as a standard by the American National Standards Institute (ANSI). ANSI also has defined 8-bit extensions to the original ASCIIcodes that provide various symbols, line shapes, and accented foreign letters for the additional 128 entries not shown in the figure. Together, the 8-bit code is known as Latin-1.Latin-1 is an ISO (International Standards Organization) standard.Both ASCII and EBCDIC have limitations that reflect their origins. The 256 code values that are available in an 8-bit word limit the number of possible characters severely.Both codes provide only the Latin alphabet, Arabic numerals, and standard punctuation characters that are used in English; Latin-1 ASCII also includes a small set of accents and other special characters that extend the set to major western European cultures.
These shortcomings led to the development of a new, mostly 16-bit, international standard, Unicode, which is quickly supplanting ASCII and EBCDIC for alphanumeric representation in most modern systems. Unicode supports approximately a million characters, using a combination of 8-bit, 16-bit and 32-bit words.The ASCII Latin-1 code set is a subset of Unicode, occupying the values 0–255 in the Unicode table, and therefore conversion from ASCII to Unicode is particularly simple: it is only necessary to extend the 8-bit code to 16 bits by setting the eight most significant bits to zero.

The most common form of Unicode, called UTF-16 can represent 65,536 characters directly, of which approximately forty-nine thousand are defined to represent the world’s most used characters. An additional 6,400 16-bit codes are reserved permanently for private use. A more recent standard, Unicode 5.0, allows for multiple code pages; presently about one hundred thousand different characters have actually been defined. Unicode is multilingual in the most global sense. It defines codes for the characters of nearly every character-based alphabet of the world in modern use, as well as codes for a large set of ideographs for the Chinese, Japanese, and Korean languages, codes for a wide range of punctuation and symbols, codes for many obsolete and ancient languages, and various control characters.Figure 4.5 shows the general code table layout for the common, 2-byte, form of Unicode.
Reflecting the pervasiveness of international communications, Unicode is gradually replacing ASCII as the alphanumeric code of choice for most systems and applications. Even IBM uses ASCII or Unicode on its smaller computers, and provides two-way Unicode-EBCDIC conversion tables for its mainframes. Unicode is the standard for use in current Windows and Linux operating systems.However, the vast amount of archival data in storage and use assures that ASCII and EBCDIC will continue to exist for some time to come.


Comments
Post a Comment