Cache Memory

If the required memory data is not already present in cache memory, an extra step is required. In this case, a cache line that includes the required location is copied from memory to the cache. Once this is done, the transfer is made to or from cache memory, as before. The situation in which the request is not already present in cache memory is known as a miss. The ratio of hits to the total number of requests is known as the hit ratio.

Cache memory works due to a principle known as locality of reference. The locality of reference principle states that at any given time, most memory references will be confined to one or a few small regions of memory. If you consider the way that you were taught to write programs, this principle makes sense. Instructions are normally executed sequentially; therefore, adjoining words are likely to be accessed. In a well-written program, most of the instructions being executed at a particular time are part of a small loop or a small procedure or function. Likewise, the data for the program is likely taken from an array. Variables for the program are all stored together. Studies have verified the validity of the locality principle. Cache memory hit ratios of 90 percent and above are common with just a small amount of cache. Since requests that can be fulfilled by the cache memory are fulfilled much faster, the cache memory technique can have a significant impact on the overall performance of the system. Program execution speed improvements of 50 percent and more are common.
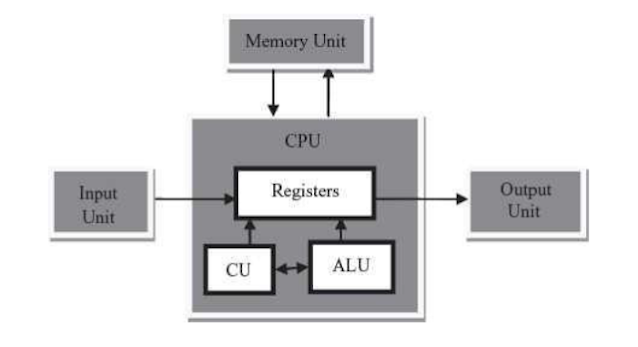
It is also possible to provide more than one level of cache memory. Consider the two level cache memory shown in Figure 8.10. This memory will work as follows. The operation begins when the CPU requests an instruction (or piece of data) be read (or written) from memory. If the cache controller for the level closest to the CPU, which we’ll call level 1 (normally abbreviated as L1), determines that the requested memory location is presently in the level 1 cache, the instruction is immediately read into the CPU.
Suppose, however, that the instruction is not presently in level 1 cache. In this case, the request is passed on to the controller for level 2 cache. Level 2 cache works in exactly the same way as level 1 cache. If the instruction is presently in the level 2 cache, a cache line containing the instruction is moved to the level 1 cache and then to the CPU. If not, then the level 2 cache controller requests a level 2 cache line from memory, the level 1 cache receives a cache line from the level 2 cache, and the instruction is transferred to the CPU. This technique can be extended to more levels, but there is usually little advantage in expanding beyond level 3.

Cache Memory: A Beginner's Guide
Cache memory is a small, high-speed storage area located close to the CPU. It stores frequently accessed data and instructions to speed up processing. Let’s dive into the basics:
1. What is Cache Memory?
- Definition: Cache memory is a type of volatile memory that provides faster data access than RAM.
- Purpose: To reduce the time the CPU spends waiting for data from the main memory (RAM).
- Speed: Faster than RAM but slower than CPU registers.
2. Why Do We Need Cache Memory?
The CPU processes data very quickly, but fetching data from RAM can slow it down. Cache acts as a "middleman" between the CPU and RAM, storing frequently accessed data to make the CPU's job faster.
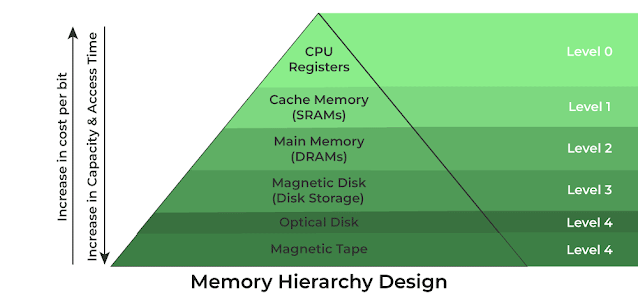
3. Levels of Cache Memory
Modern computers typically have multiple levels of cache, organized hierarchically:
a. L1 Cache (Level 1)
- Location: Built directly into the CPU core.
- Speed: Fastest among all cache levels.
- Size: Small, usually 16KB to 128KB.
- Purpose: Stores the most critical data and instructions.
b. L2 Cache (Level 2)
- Location: Located on the CPU chip but not in the core.
- Speed: Slightly slower than L1 but still faster than RAM.
- Size: Larger than L1, typically 128KB to 4MB.
- Purpose: Holds additional data and instructions not found in L1.
c. L3 Cache (Level 3)
- Location: Shared among all CPU cores.
- Speed: Slower than L1 and L2 but faster than RAM.
- Size: Larger, ranging from 4MB to 50MB.
- Purpose: Reduces bottlenecks when multiple CPU cores need data.
4. How Does Cache Work?
Here’s a simple step-by-step example:
- Request: The CPU requests data to perform an operation.
- Check Cache: The cache is checked first. If the data is found, it's called a "cache hit."
- Fetch from RAM: If the data is not in the cache, it's called a "cache miss," and the data is fetched from RAM and stored in the cache for future use.
- Provide Data: The CPU gets the data quickly and continues processing.
5. How is Cache Organized?
Cache memory uses blocks to store data, and it employs different strategies to decide:
- Which data to store: Often based on what the CPU uses most frequently.
- Which data to remove: Least Recently Used (LRU) and First In First Out (FIFO) are common strategies.
6. Advantages of Cache Memory
- Speed: Significantly improves CPU performance.
- Efficiency: Reduces the need to access slower RAM.
- Responsiveness: Helps with real-time processing and smooth multitasking.
7. Disadvantages of Cache Memory
- Cost: Expensive compared to RAM.
- Limited Size: Small storage capacity.
- Complexity: Adds complexity to CPU design.
8. Analogy to Understand Cache
Imagine you’re studying from a textbook.
- Registers: The notes you're holding in your hand for immediate use.
- Cache: The frequently used pages of your textbook bookmarked for quick reference.
- RAM: The entire textbook sitting on your desk.
- Hard Disk: The bookshelf where all your textbooks are stored.
Summary
Cache memory is essential for reducing the CPU's waiting time and improving overall performance. It bridges the speed gap between the CPU and RAM, ensuring smoother and faster processing.All of these examples of caching share the common attribute that they increase performance by providing faster access to data, anticipating its potential need in advance, then storing that data temporarily where it is rapidly available.
Thank you sir
ReplyDelete